Async task fixes and new async calculation of resource size#3028
Conversation
Codecov Report
@@ Coverage Diff @@
## hotfixes #3028 +/- ##
============================================
+ Coverage 80.80% 85.93% +5.13%
============================================
Files 281 304 +23
Lines 12659 16403 +3744
============================================
+ Hits 10229 14096 +3867
+ Misses 2430 2307 -123
Continue to review full report at Codecov.
|

| CELERY_TASK_SERIALIZER = 'json' | ||
| CELERY_RESULT_SERIALIZER = 'json' | ||
| # This is needed for worker update_state calls to work so they can send progress info. | ||
| CELERYD_STATE_DB = '/tmp/celery_state' |
There was a problem hiding this comment.
As far as I know, we're not using the Celery daemon, so this wasn't being used.
| CELERY_TASK_ALWAYS_EAGER = False | ||
| # This tells Celery to mark a task as started. Otherwise, we would have no way of tracking | ||
| # if the task is running. | ||
| CELERY_TASK_TRACK_STARTED = True |
There was a problem hiding this comment.
Moved this to the CeleryTask class, so it's closer to the task definition. We likely don't want to change this value anyway.
|
|
||
|
|
||
| @task(bind=True, name="duplicate_nodes_task") | ||
| @app.task(bind=True, name="duplicate_nodes_task", track_progress=True) |
There was a problem hiding this comment.
Task boolean for tracking progress is now configurable at the task definition.
| "export-channel": export_channel_task, | ||
| "sync-channel": sync_channel_task, | ||
| "get-node-diff": generatenodediff_task, | ||
| "calculate-resource-size": calculate_resource_size_task, |
There was a problem hiding this comment.
We could get rid of this in the future, if we align the task_name sent to create_async_task() with the names of the tasks we define for Celery. Right now, they're slightly different
There was a problem hiding this comment.
Yeah, I always found this mapping odd, when Celery explicitly has you define a name for the task.
| self.assertEqual(data["status"], "STARTED") | ||
| self.assertEqual(data["task_type"], "YOUTUBE_IMPORT") | ||
| self.assertIsNotNone(data["channel"]) | ||
| self.assertEqual(data["channel"].hex, self.channel.id) |
There was a problem hiding this comment.
I don't exactly understand why I needed .hex for the value coming from the task api response
There was a problem hiding this comment.
DRF test tools take a shortcut and don't actually serialize and deserialize, instead passing the raw Python objects out as the response data. I really hate it. So because something was parsed as a UUID, it comes out as a UUID here.
| try: | ||
| task = Task.objects.get(task_id=task_id) | ||
| task.status = "PENDING" | ||
| task.status = states.PENDING |
There was a problem hiding this comment.
Updated all states to use the Celery constants.
| Ensures status is updated after task completion, otherwise our signals may not fire | ||
| """ | ||
| # we assume that if the state is past starting, that this has been handled | ||
| if states.state(status) > states.state(states.STARTED): |
There was a problem hiding this comment.
Celery has some nice utils for state handling.
 rtibbles
left a comment
rtibbles
left a comment
There was a problem hiding this comment.
A few questions - but I don't think there's anything blocking.
| source_url = models.CharField(max_length=400, blank=True, null=True) | ||
| uploaded_by = models.ForeignKey(User, related_name='files', blank=True, null=True, on_delete=models.SET_NULL) | ||
|
|
||
| modified = models.DateTimeField(auto_now=True, verbose_name="modified", null=True) |
There was a problem hiding this comment.
This should generally work fine - as new files are created one at a time, and so will have the modified set by auto_now. File updating is done in bulk, so as far as I can tell this will not update auto_now (I think this may be affecting our updates of ContentNodes too - so I might need to file a separate issue for that).
The only thing this might miss is file deletion or node deletion, where node deletion will normally be a move to the trash tree. Wonder if we might have to look at node modified as well?
There was a problem hiding this comment.
Ah good catch, I definitely overlooked the deletion case. I'm thinking that in the case of node/file deletion/move, we could set the cache modified date to the modified date of the earliest date of the associated files prior to the change, if that time is less than the existing cache modified. So if that deleted item was the most recent, and it was included in calculation previously, that date should still be prior to the cache modified. Otherwise, it would almost always be the case, so triggering an update of the cache. Do you think that can work? Am I overlooking anything in that strategy?
Re file updating: yeah that could definitely be an issue with the modified field specifically. It seemed to me that there weren't many cases where a file would be updated in a way that would cause its resource size to change. But rethinking it now, if the file is removed from the content node, surely we would need to trigger change the cache modified time.
There was a problem hiding this comment.
Also, the existing calculation didn't include assessment items.... that should be included too, correct?
There was a problem hiding this comment.
After a quick slack convo - I think I know what this means now!
So yes, let's update the cache modified when files are deleted, based on the deleted file's modified date, and take the min of the last modified date for all files when we move a content node.
I think we can skip assessment items for now, to avoid making this PR more unmanageable, but we should be considering them, ideally!
| class TaskViewSet(ReadOnlyValuesViewset, DestroyModelMixin): | ||
| queryset = Task.objects.all() | ||
| order_by = 'created' | ||
| queryset = Task.objects.order_by(order_by) |
There was a problem hiding this comment.
Could also just add it as the default ordering on the Task model?
| ) | ||
|
|
||
| @detail_route(methods=["get"]) | ||
| @action(detail=True, methods=["get"]) |
There was a problem hiding this comment.
Just trying to give me merge conflicts in my Django 3 PR!
| size, stale = calculate_resource_size(node=node, force=False) | ||
| if stale: | ||
| task_args = dict(node_id=node.pk, channel_id=node.channel_id) | ||
| task_info = get_or_create_async_task( |
There was a problem hiding this comment.
Because it took me all afternoon to realize it - might be good to add a comment here that get_or_create_async_task is being used here to prevent a cache stampede.
- Update resource size cache modified date when moving nodes or deleting files - Relcoate ResourceSizeCache to avoid import issues - Only allow size calculations for root nodes through the API
rtibbles
left a comment
There was a problem hiding this comment.
New code changes make sense to me. I'll try to take it for a spin this afternoon for manual sanity checking!
|
Manual testing generally worked out, but in this scenario:
I found the size did not update again after step 5, but then did properly update when I moved the node in question to trash. |
rtibbles
left a comment
There was a problem hiding this comment.
File deletion now resetting cache as expected!
|
@bjester today I tested this PR at https://hotfixes.studio.learningequality.org/. Here's a summary of my observations: Large channel scenario: This scenario fails, I'm testing with a channel with 5000+ resources and I'm always getting a message about an unexpected error (seems that the size request timeouts). See the following screenshot: By the way I didn't see a loading spinner as described in the scenario do you mean the progress bar? Deleting a file scenario or Moving a node scenario: I tested these with a very small channel but I'm still getting the /api/get_total_size timeout as described in #1523. See the following screenshot: Here's what I get when testing with another user (cenov1@melon.bg) where I also see a 400 error for api/sync: |
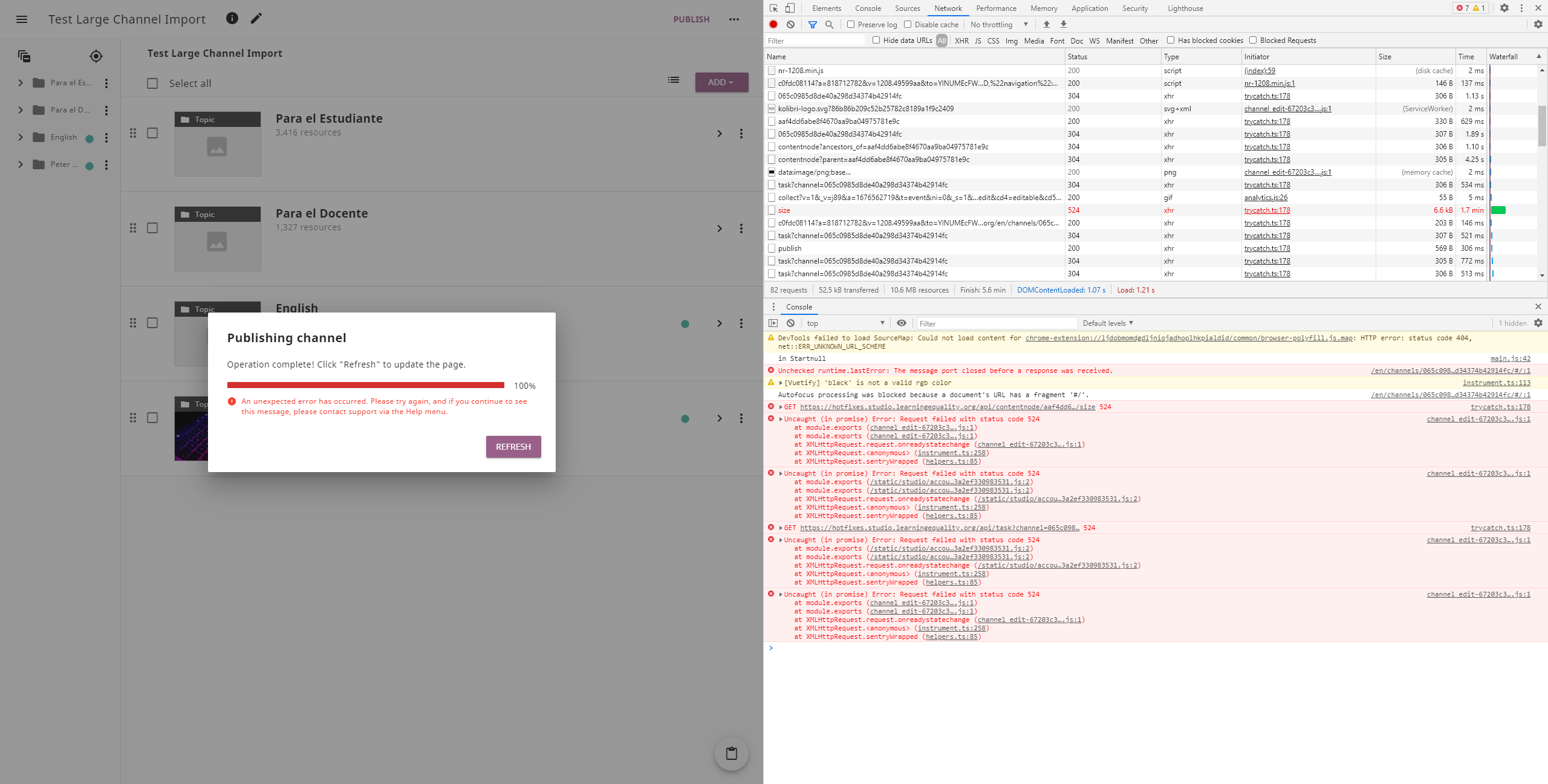
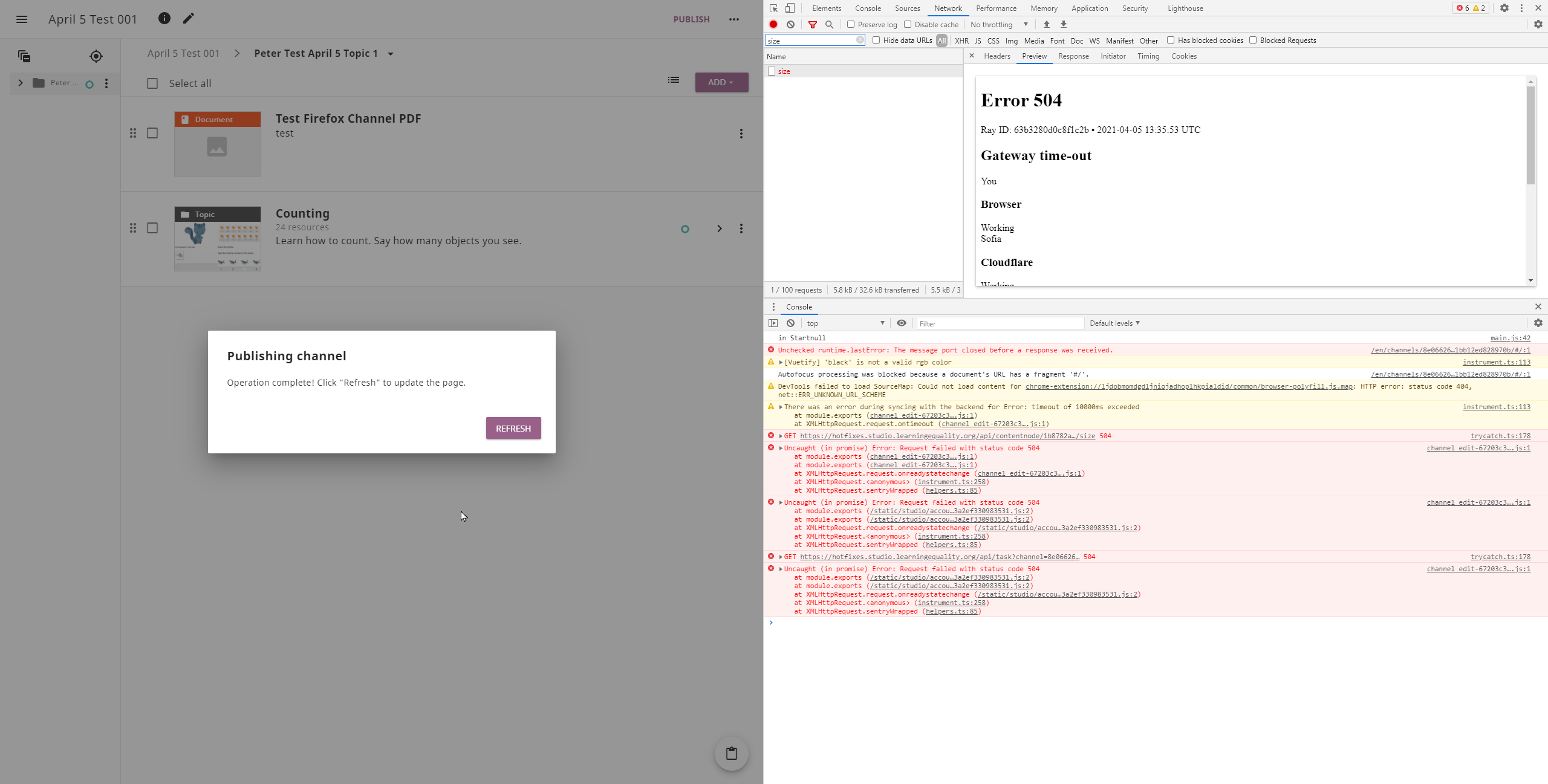
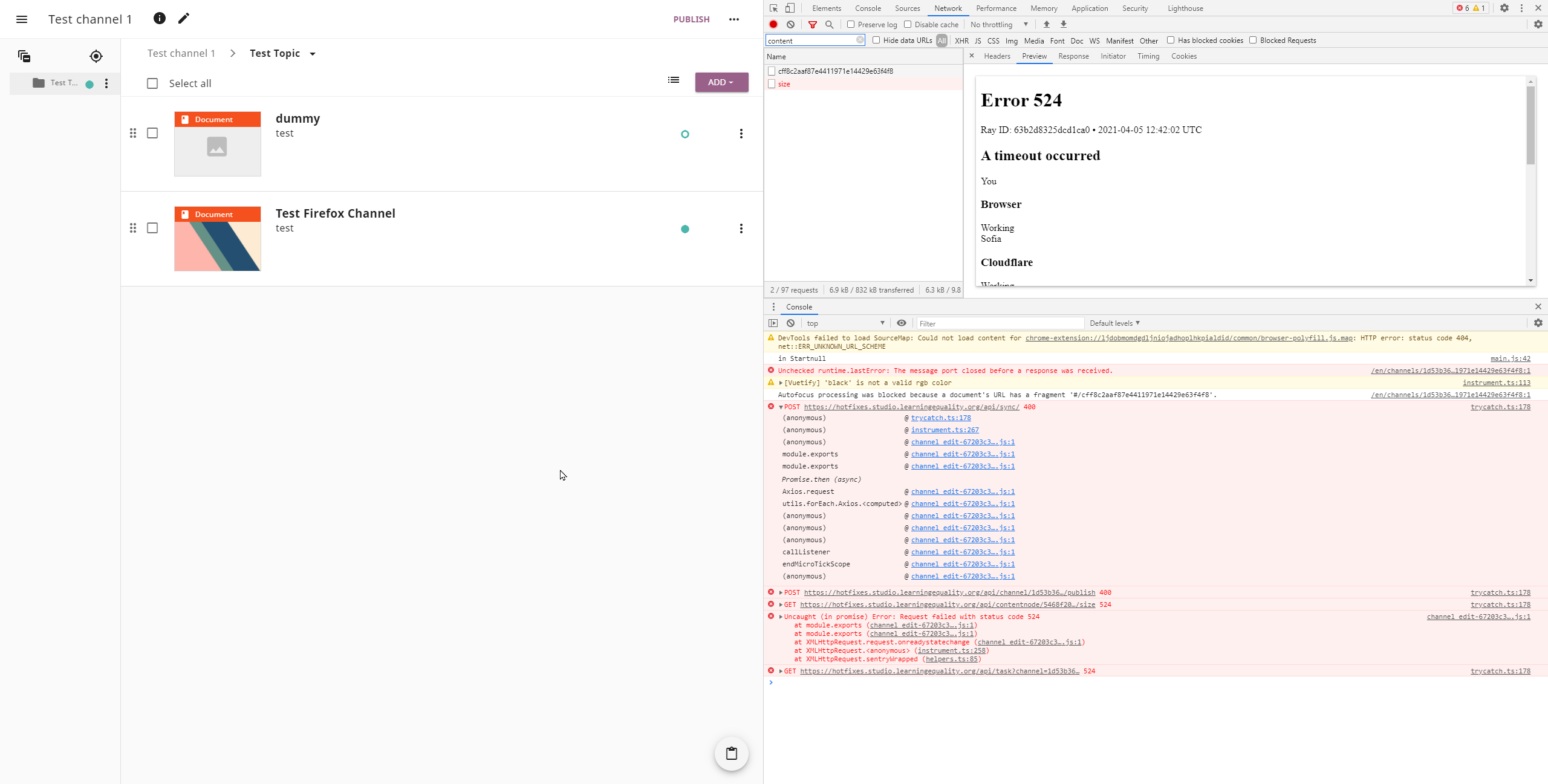
|
On my side I eventually managed to publish a large channel: despite occasional 524 and 504 errors in the console and the network tab, nothing was observable in the user interface, and channel (
I also did not observe the loading spinner while publishing, does it appear only if there are incomplete resources? |
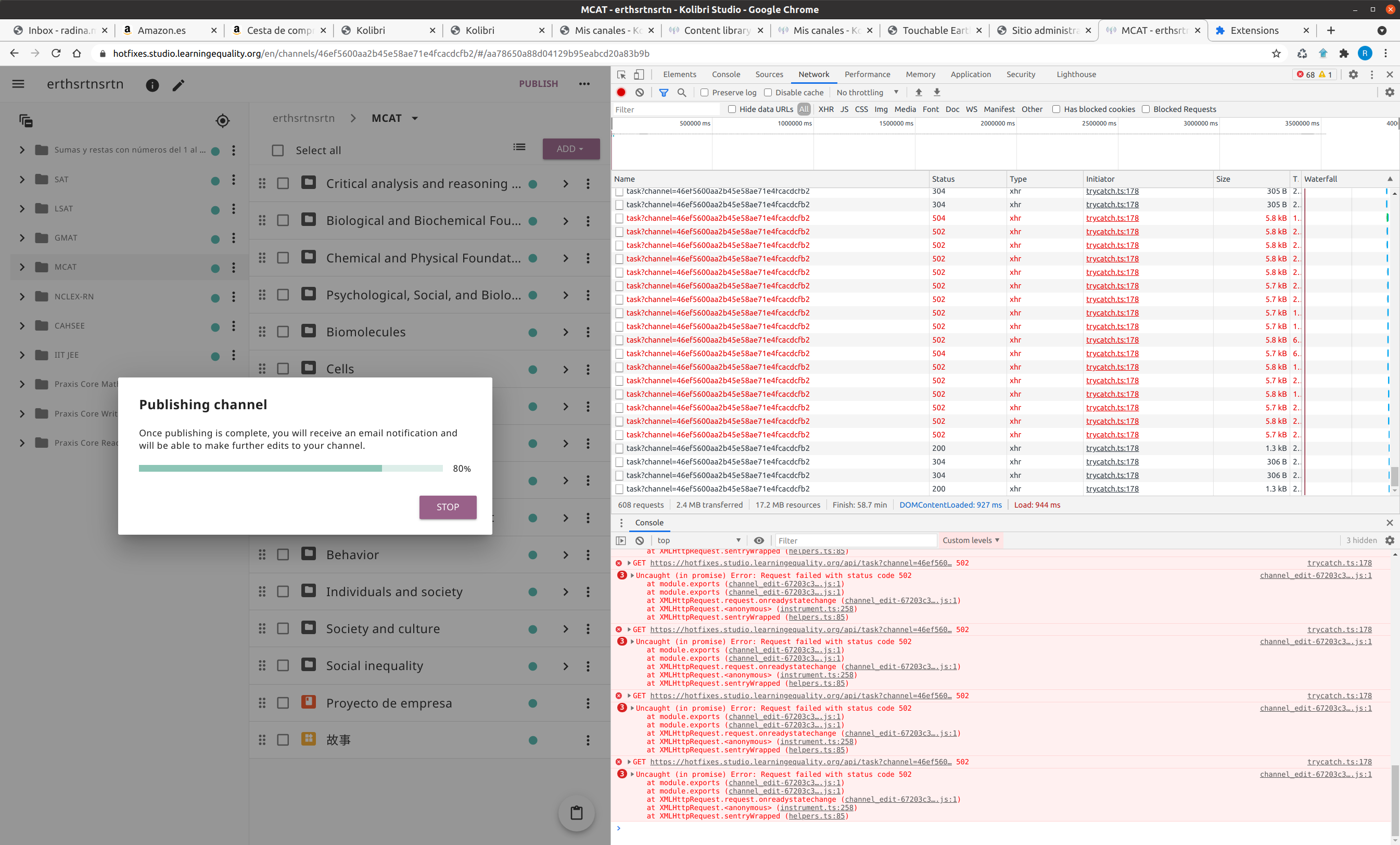
|
@pcenov @radinamatic Very interesting, since 5000+ resources should queue the calculation task asynchronously, I wonder if there's a larger issue going on with hotfixes right now. The loading spinner should occur in the modal before the actual publish process, so no the progress bar and loading spinner are not the same. Definitely seems as though something isn't quite right with hotfixes. |
|
Ok, now I do see it, although not sure how helpful it is: it appears only while the user is on the first step of the modal, writing the version comment/note, before the publishing process has even started. What exactly it is supposed to communicate to the user, compared to the progress bar when the publishing task is active? 🤔 |
|
It's literally just there to show that we are still loading the total size for the channel. |
|
In that case we might consider adding a string Loading total channel size... at some point in the future, alongside that spinner 🙁 |
|
@radinamatic Yes, sounds good. I believe @MisRob has a bunch of updates to the publish modals in the |
Summary
Description of the change(s) you made
modifiedfield to File model to use in determining if cache is stale thereby avoiding unnecessary calculations and the overhead it bringsManual verification steps
Note: it may be useful to use the browser's network inspector to validate the size changes. Filter network requests by
sizeand use the Preview tab of the request to inspect the response JSON which holds the size in bytesLarge channel scenario
Deleting a file scenario
/api/contentnode/sizerequest/api/contentnode/sizerequest is different than you noted originallyMoving a node scenario
/api/contentnode/sizerequest/api/contentnode/sizerequest is different than you noted originallyScreenshots (if applicable)
Reviewer guidance
How can a reviewer test these changes?
Are there any risky areas that deserve extra testing?
References
Addresses: #1523
Addresses: #2658
Addresses: #2953
Contributor's Checklist
PR process:
requirements.txtfiles also included in this PRTesting:
Reviewer's Checklist
yarnandpip)